

Si alguna vez habéis oído hablar de webscraping y no sabéis qué es, este post es para vosotros.
Webscraping es una técnica que se utiliza para tratar de obtener información estructurada de una página web de forma automática.
Por ejemplo, las páginas web que te permiten comparar precios de productos electrónicos entre varias tiendas utilizan webscraping para obtener los precios de páginas como Amazon, Mediamarkt, etc
En este caso vamos a ver una solución fácil y sencilla que nos puede permitir adentrarnos en el mundo del webscraping en páginas sencillas.
1. Conocimientos previos: código HTML
Antes de adentrarnos en python a programar nuestro webscraper, es necesario que conozcamos la estructura básica de HTML, lenguaje estándar en el que se escriben todas las páginas web y que permite interpretar la web a cualquier navegador (por eso lo de estándar).
1.1. Las «etiquetas» de HTML
HTML se estructura en «elementos» y «atributos» (de los elementos):
a) Elementos
Cuando se quiere iniciar un «elemento» se invoca como <nombre del elemento>, se escribe el contenido y cuando se ha terminado, se cierra el elemento con la siguiente estructura </nombre del elemento>.
Un ejemplo podría ser:
<strong> Soy un texto en negrita </strong>
Si este texto lo pegamos y guardarnos en un bloc de notas y cambiamos la extensión a .html, tendremos nuestra «primera página web».
b) Atributos
Son ciertas características que pueden tener los elementos. Siempre se estructura como <nombre del elemento atributo=»valor»> incluimos el contenido y cerramos con </nombre del elemento>
Por ejemplo, vamos a generar un enlace a Google:
<a href="http://www.google.es" title="Ejemplo de enlace a Google"> Ejemplo Google </a>
1.2. ¿Cómo podemos ver el código HTML de una página web?
En todos los navegadores modernos encontramos una función que se llama «Ver código fuente de la página» para identificar los elementos html que queremos:

2. Creando nuestro webscraper básico
Vamos a utilizar la web de la Metropolitan Transportation Authority para el ejemplo. En este caso queremos descargar todos los enlaces txt de la web http://web.mta.info/developers/turnstile.html
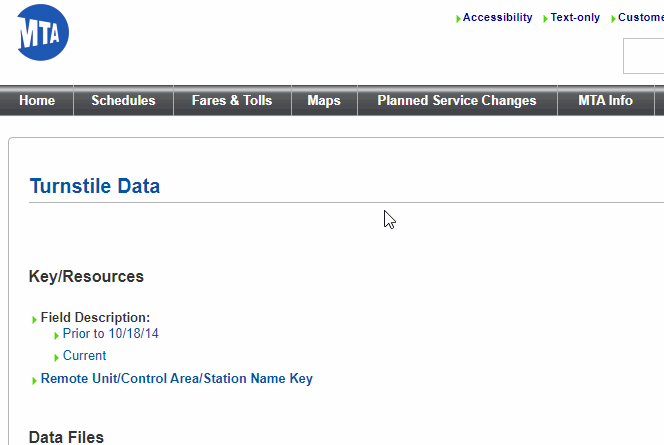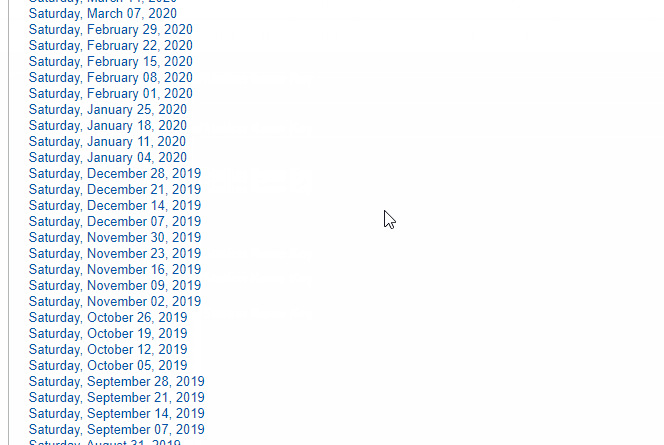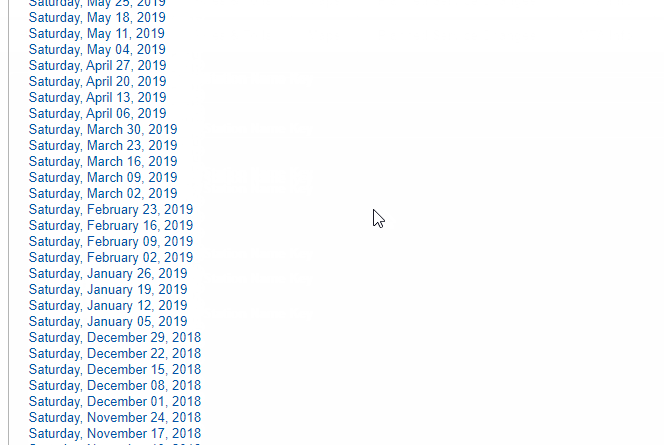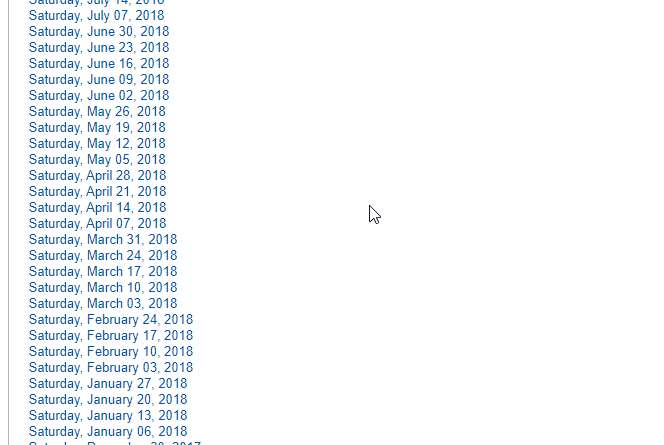
a) Inspeccionar la estructura HTML de la web
Inicialmente debemos revisar el código de la web para identificar los trozos de código html que queremos extraer de la web. Tal y como vemos en la imagen, el «elemento» que queremos seleccionar es <a>, que tiene un atributo href que contiene «parte» del enlace de la url de los txt que queremos :
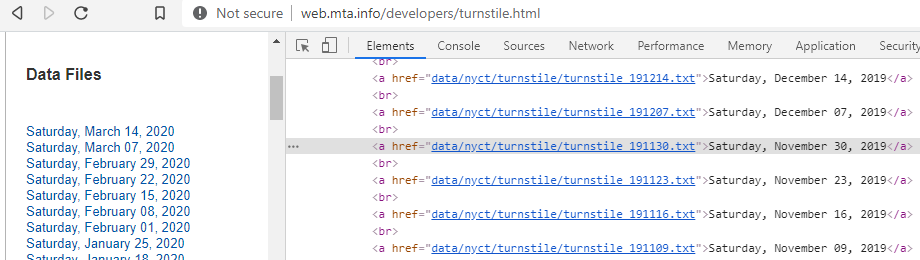
Decimos que contiene «parte» de la url del archivo txt que queremos puesto que, si introducimos en nuestro navegador la dirección «data/nyct/turnstile/turnstile_191130.txt» debemos incluir la url completa, que sería: » http://web.mta.info/developers/data/nyct/turnstile/turnstile_191130.txt «
b) Librerías request y BeautifulSoup
– Request: librería que nos permite, entre otras cosas, acceder a una web, conocer la respuesta del servidor a nuestra solicitud de acceso y descargar la misma en formato html a nuestro pc
– BeautifulSoup: librería que nos seleccionar contenido html de una web. Toda la documentación en su web: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
# Importamos las librerías import bs4,requests #Almacenamos la url en una variable url_busqueda="http://web.mta.info/developers/turnstile.html" #Pasamos la url a request para verificar que el servidor nos da acceso a la web y nos descarga la web en html en el objeto url_request url_request=requests.get(url_busqueda) url_request.raise_for_status
Si obtenemos una respuesta «Response 200» quiere decir que hemos logrado tener acceso a la web sin problema.
Tal y como hemos dicho, se habrá creado un objeto de clase request que contiene TODO EL CÓDIGO DE LA WEB EN UN STRING (cadena de texto). Se puede ver a través «[nombre de tu variable].text», en nuestro caso, url_request.text:

Ahora falta obtener los elementos «<a>» del string almacenado en url_request.text.
Para ello:
1. Creamos un objeto de clase BeautifulSoup y le pasamos el contenido html de la web almacenado como string.
2. Seleccionamos las etiquetas html que nos interesen, en este caso las etiquetas <a> que son las que contienen urls
# Iniciamos el objeto mta de clase BeautifulSoup con el contenido
# de html de la web almacenado en "url_request.text"
mta=bs4.BeautifulSoup(url_request.text)
# Seleccionamos la etiqueta html que nos interesa, en este caso, <a>
enlaces_mta=mta.select("a")
# Vemos el resultado
enlaces_mta
Si todo ha salido bien, obtendremos un listado con todas las urls de la web:

Por último, nos faltaría obtener un listado con los enlaces eliminando todas las partes de código html que no nos interesan:
# Inicializamos lista para almacenar enlaces:
enlaces=[]
# Separamos cada enlace referenciado como "href" en una lista
for link in enlaces_mta:
enlaces.append(link.get("href"))
# Hacemos un print de la lista para ver los enlaces. En nuestro caso 550 enlaces almacenados
for enlace in enlaces:
print(enlace)
Y este sería «casi» el resultado final:

Si queremos seleccionar solo las urls que empiezan con «data» para poder acceder a los archivos .txt como era nuestra primera intención, podemos crear una nueva lista de enlaces con solo las url «data»:
enlaces_data=[]
for enlace in enlaces:
if str(enlace).startswith("data/"):
enlaces_data.append("http://web.mta.info/developers/"+str(enlace))
print("Listado de enlaces descargados de la web: \n")
for enlace in enlaces_data:
print(enlace)
Y ahora sí que sí tendríamos el resultado final:

A continuación dejo el código completo:
# Importación de librerías a usar
import bs4,requests
#Almacenamos la url en una variable
url_busqueda="http://web.mta.info/developers/turnstile.html"
#Pasamos la url a request para verificar que el servidor nos da acceso a la web y nos descarga la web en html en el objeto url_request
url_request=requests.get(url_busqueda)
print("Respuesta del servidor a nuestra solicitud de consulta a la web: \n"+str(url_request.raise_for_status))
# Iniciamos el objeto mta de clase BeautifulSoup con el contenido
# de html de la web almacenado en "url_request.text"
mta=bs4.BeautifulSoup(url_request.text)
enlaces_mta=mta.select("a")
# Inicializamos lista para almacenar enlaces:
enlaces=[]
print("\n")
# Separamos cada enlace referenciado como "href" en una lista
for link in enlaces_mta:
enlaces.append(link.get("href"))
# Print "comentado" por si se quiere ver la lista para ver los enlaces. En nuestro caso 550 enlaces almacenados
#for enlace in enlaces:
# print(enlace)
# Nos quedamos solo con las urls que inician por "data" ya que son las que nos interesan.
# En el mismo paso, incluimos la primera parte "http://web.mta.info/developers/" para que sea accesible la url
enlaces_data=[]
for enlace in enlaces:
if str(enlace).startswith("data/"):
enlaces_data.append("http://web.mta.info/developers/"+str(enlace))
print("Listado de enlaces descargados de la web: \n")
for enlace in enlaces_data:
print(enlace)